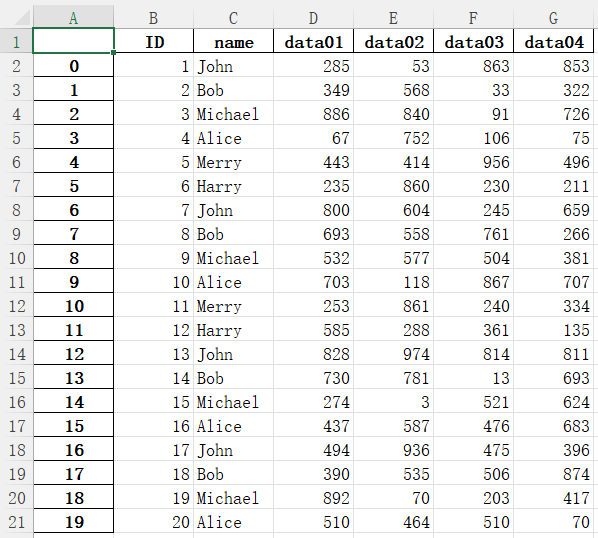
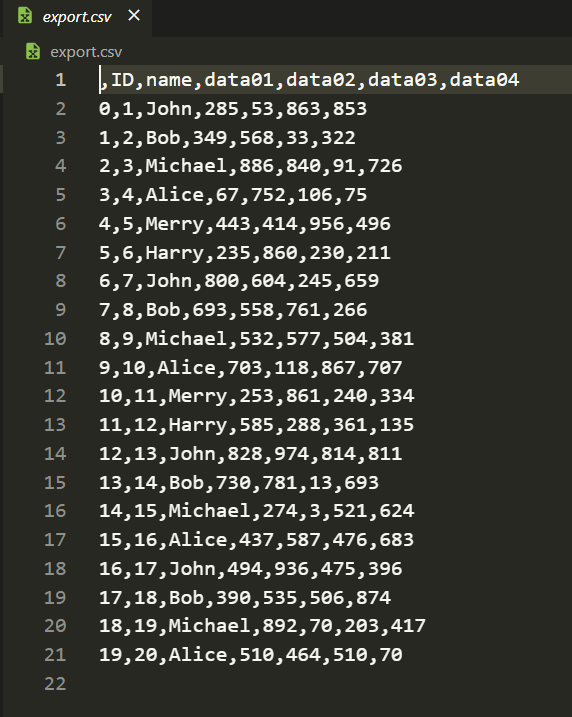
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| Traceback (most recent call last):
File "e:\pyCode\pandas\test.py", line 14, in <module>
print(df.max(axis=1))
File "C:\Users\pandas_test\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\generic.py", line 11646, in max
return NDFrame.max(self, axis, skipna, numeric_only, **kwargs)
File "C:\Users\pandas_test\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\generic.py", line 11185, in max
return self._stat_function(
File "C:\Users\pandas_test\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\generic.py", line 11158, in _stat_function
return self._reduce(
File "C:\Users\pandas_test\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\frame.py", line 10524, in _reduce
res = df._mgr.reduce(blk_func)
File "C:\Users\pandas_test\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\internals\managers.py", line 1534, in reduce
nbs = blk.reduce(func)
File "C:\Users\pandas_test\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\internals\blocks.py", line 339, in reduce
result = func(self.values)
File "C:\Users\pandas_test\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\frame.py", line 10487, in blk_func
return op(values, axis=axis, skipna=skipna, **kwds)
File "C:\Users\pandas_test\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\nanops.py", line 158, in f
result = alt(values, axis=axis, skipna=skipna, **kwds)
File "C:\Users\pandas_test\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\nanops.py", line 421, in new_func
result = func(values, axis=axis, skipna=skipna, mask=mask, **kwargs)
File "C:\Users\pandas_test\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\nanops.py", line 1094, in reduction
result = getattr(values, meth)(axis)
File "C:\Users\pandas_test\AppData\Local\Programs\Python\Python310\lib\site-packages\numpy\core\_methods.py", line 41, in _amax
return umr_maximum(a, axis, None, out, keepdims, initial, where)
TypeError: '>=' not supported between instances of 'int' and 'str'
|